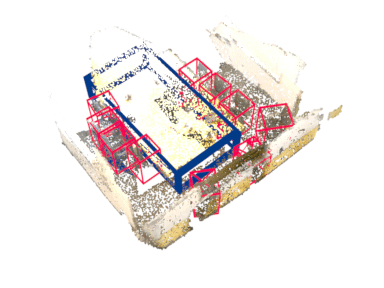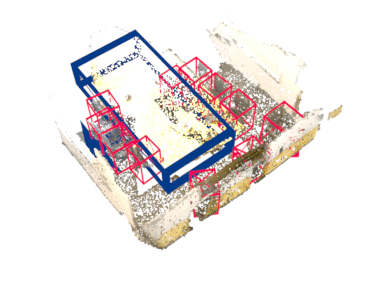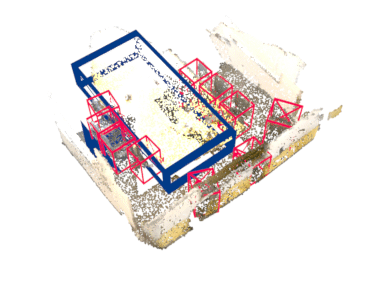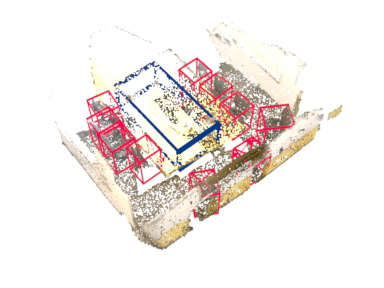
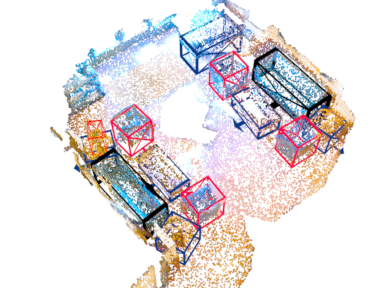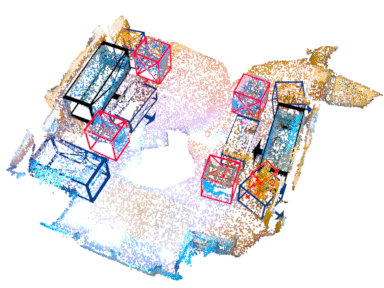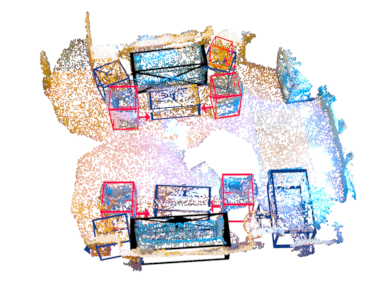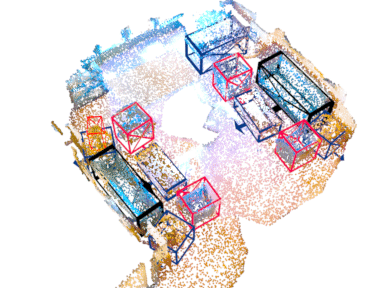
Abstract
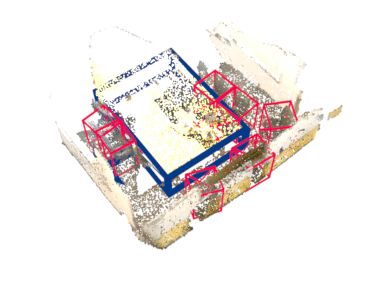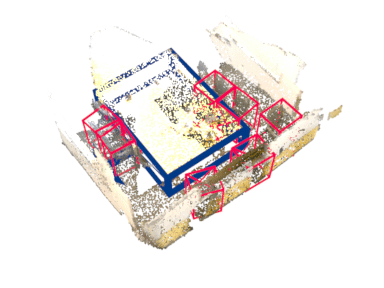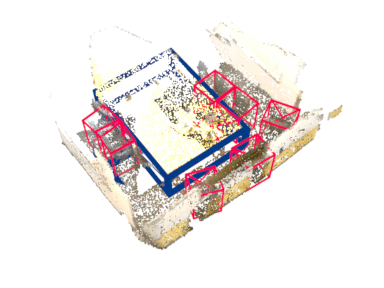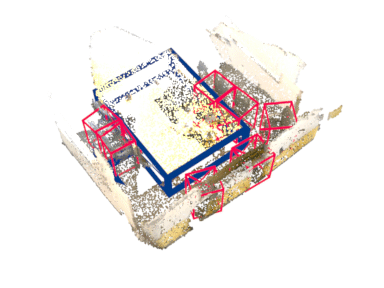
Rotation equivariance has recently become a strongly desired property in the 3D deep learning community. Yet most existing methods focus on equivariance regarding a global input rotation while ignoring the fact that rotation symmetry has its own spatial support. Specifically, we consider the object detection problem in 3D scenes, where an object bounding box should be equivariant regarding the object pose, independent of the scene motion. This suggests a new desired property we call object-level rotation equivariance. To incorporate object-level rotation equivariance into 3D object detectors, we need a mechanism to extract equivariant features with local object-level spatial support while being able to model cross-object context information. To this end, we propose Equivariant Object detection Network (EON) with a rotation equivariance suspension design to achieve object-level equivariance. EON can be applied to modern point cloud object detectors, such as VoteNet and PointRCNN, enabling them to exploit object rotation symmetry in scene-scale inputs. Our experiments on both indoor scene and autonomous driving datasets show that significant improvements are obtained by plugging our EON design into existing state-of-the-art 3D object detectors.
Video
Quantitative Results
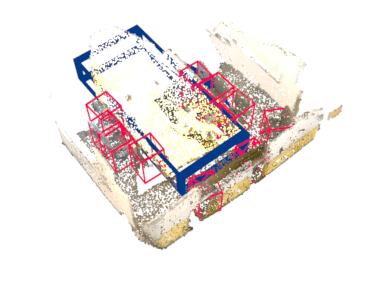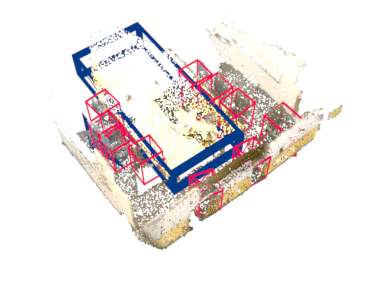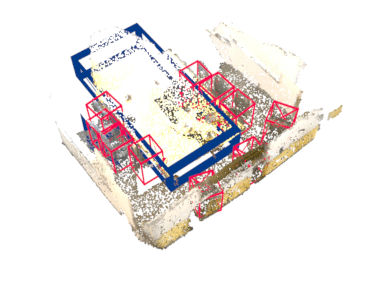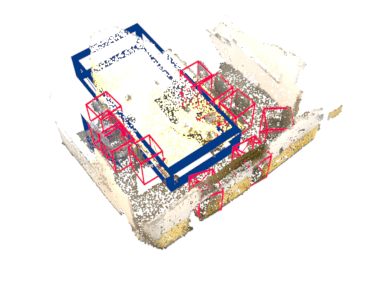
Our method works on both indoor and outdoor datasets, different 3D detector architectures, and different backbones.
Indoor (ScanNet V2)
| Method | VoteNet[1] | EON-VoteNet (Ours) | Transformer[2] | EON-Transformer (Ours) |
|---|---|---|---|---|
| mAP | 50.4 | 56.7 | 52.4 | 57.2 |
Outdoor (KITTI 3D)
| Method | PointRCNN[3] | EON-PointRCNN (Ours) |
|---|---|---|
| Ped-AP | 55.9 | 61.1 |
BibTeX